In cloud-native environments, managing high availability for complex database clusters is a core challenge for enterprises. KubeBlocks, an open-source multi-engine database management platform, is dedicated to ensuring the stability of database services in various failure scenarios. However, traditional testing methods struggle to simulate complex failures in real production environments, making it difficult to fully validate system resilience.
Chaos engineering, by actively injecting controllable failures, helps discover system weaknesses early and drives system hardening. Through systematic testing based on Chaos Mesh, we validated KubeBlocks' high availability performance in scenarios such as host anomalies, process anomalies, network anomalies, pressure anomalies, and system service anomalies: primary node failover in seconds, zero data loss, and summarized a series of best practices.
This article will introduce how to leverage the Chaos Mesh tool to validate and enhance KubeBlocks' high availability capabilities through fault injection exercises.
Chaos Mesh is an open-source chaos engineering platform used for chaos testing of distributed systems in Kubernetes environments. By simulating faults and anomalies (such as network latency, service failures, resource exhaustion, etc.), Chaos Mesh helps developers and operations personnel validate system stability, fault tolerance, and high availability.
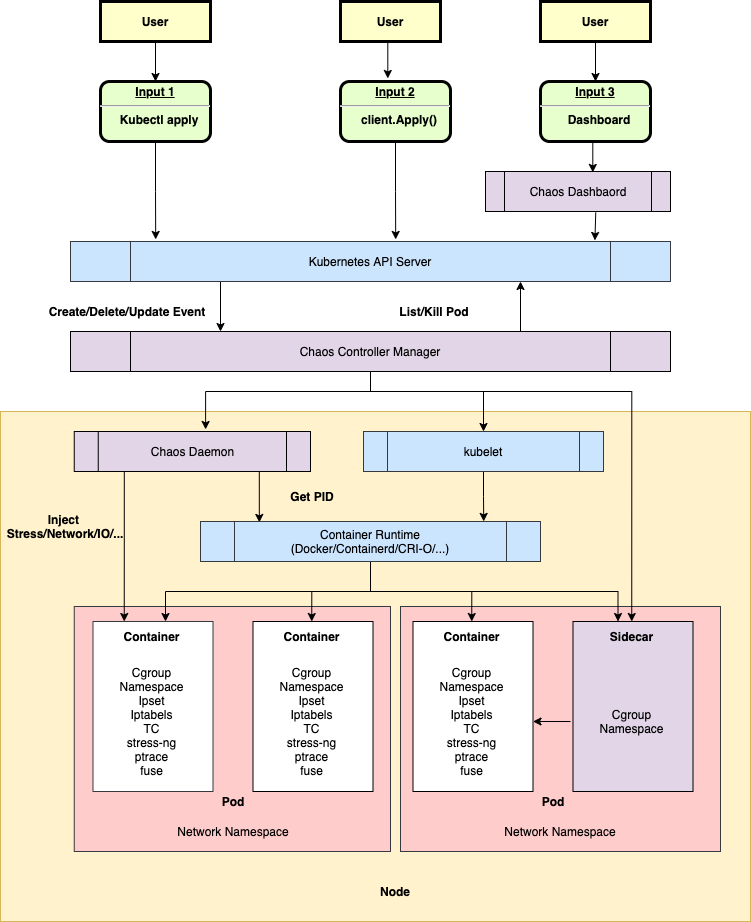
Architecture Diagram
Chaos Mesh aligns with KubeBlocks' database management scenarios due to its native K8s integration, fine-grained fault control capabilities, and declarative experiment management.
Through declarative experiments, KubeBlocks' core high availability capabilities were validated: primary node failover in seconds, zero data loss, and continuous optimization of the multi-engine architecture was driven, providing a quantifiable and reproducible fault testing baseline for cloud-native database resilience.
| Fault Type | Simulated Scenario | Expected Behavior | Validation Goal |
|---|---|---|---|
| PodChaos | Primary node Pod forced deletion | Secondary node quickly promotes to new primary; application connection briefly interrupted then restored | Primary node election, failover time |
| PodChaos | Single replica Pod continuous restarts | Service availability unaffected; replica set automatically recovers | Effectiveness of replica redundancy |
| NetworkChaos | Primary node network latency (1000ms+) | Triggers primary node disconnection; cluster elects new primary | Network partition tolerance, split-brain protection |
| NetworkChaos | 100% packet loss between primary and secondary nodes | Primary-secondary replication delay increases; eventual consistency ensured | Robustness of asynchronous replication |
| NetworkChaos | Network partition between nodes | Majority partition continues serving; minority partition becomes unwritable | Partition tolerance (PACELC) |
| StressChaos | Primary node CPU overload (100%) | Primary node response slows down; may trigger liveness probe timeout leading to Failover | Resource isolation, resource overload protection, probe sensitivity |
| StressChaos | Secondary node memory pressure (OOM simulation) | Secondary process crashes; K8s automatically restarts replica | Resource isolation, process recovery capability |
| DNSChaos | Random internal DNS resolution failures within cluster | Inter-replica communication occasionally fails; relies on retry mechanism for recovery | Service discovery reliability, client retries |
| TimeChaos | Primary node clock jumps forward 2 hours | May cause Raft Term confusion or expired transactions, triggering primary node eviction | Clock drift sensitivity, logical clock assurance |
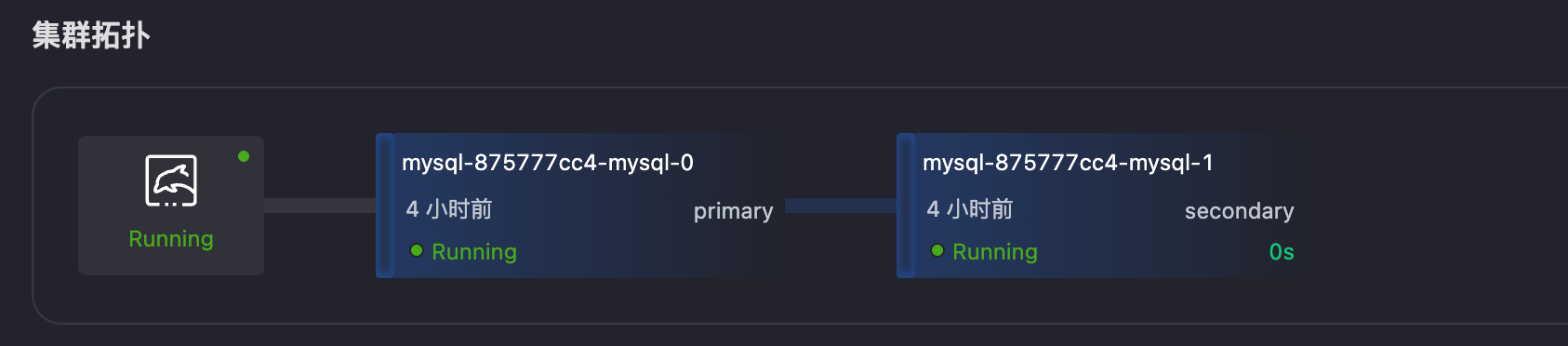
Taking the primary node Pod forced deletion scenario as an example:
chaos-experiment.yaml for the corresponding fault scenario.apiVersion: chaos-mesh.org/v1alpha1
kind: PodChaos
metadata:
name: test-primary-pod-kill
namespace: default
spec:
action: pod-kill
mode: one
selector:
namespaces:
- kubeblocks-cloud-ns
labelSelectors:
app.kubernetes.io/instance: mysql-875777cc4
kubeblocks.io/role: primary
kubectl apply -f chaos-experiment.yaml.kubectl describe PodChaos test-primary-pod-kill
Status:
Experiment:
Container Records:
Events:
Operation: Apply
Timestamp: 2025-07-18T07:55:17Z
Type: Succeeded
Id: kubeblocks-cloud-ns/mysql-875777cc4-mysql-0
Injected Count: 1
Phase: Injected
Recovered Count: 0
Selector Key: .
Desired Phase: Run
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal FinalizerInited 15m initFinalizers Finalizer has been inited
Normal Updated 15m initFinalizers Successfully update finalizer of resource
Normal Updated 15m desiredphase Successfully update desiredPhase of resource
Normal Applied 15m records Successfully apply chaos for kubeblocks-cloud-ns/mysql-875777cc4-mysql-0
Normal Updated 15m records Successfully update records of resource
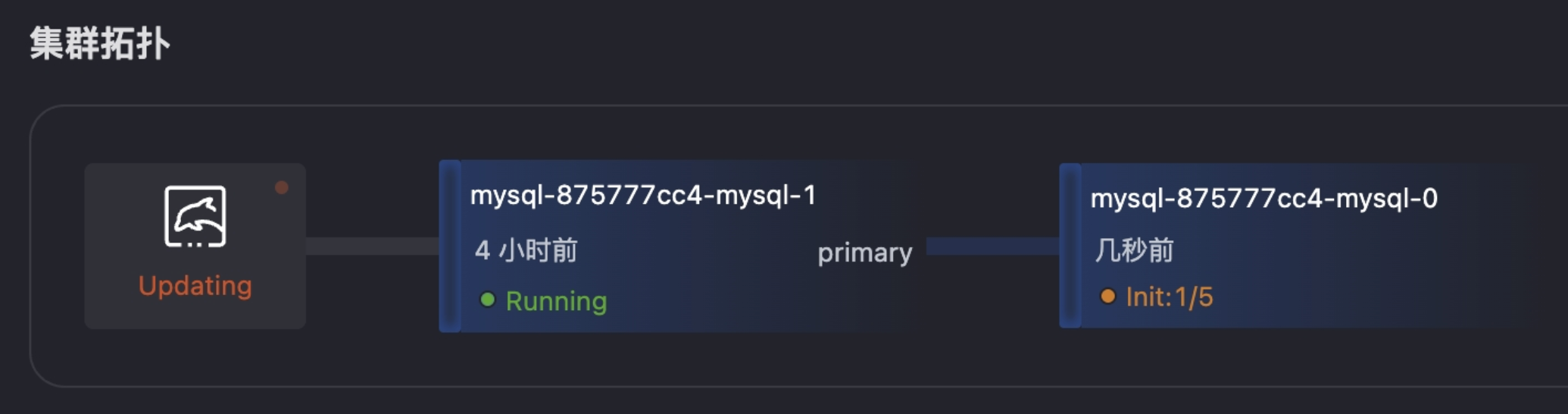
kubectl logs -n kubeblocks-cloud-ns mysql-875777cc4-mysql-1 lorry
2025-07-18T07:55:17Z INFO DCS-K8S pod selector: app.kubernetes.io/instance=mysql-875777cc4,app.kubernetes.io/managed-by=kubeblocks,apps.kubeblocks.io/component-name=mysql
2025-07-18T07:55:18Z INFO DCS-K8S podlist: 2
2025-07-18T07:55:18Z INFO DCS-K8S members count: 2
2025-07-18T07:55:18Z DEBUG checkrole check member {"member": "mysql-875777cc4-mysql-0", "role": ""}
2025-07-18T07:55:18Z DEBUG checkrole check member {"member": "mysql-875777cc4-mysql-1", "role": "secondary"}
2025-07-18T07:55:18Z INFO event send event: map[event:Success operation:checkRole originalRole:secondary role:{"term":"1752825318001682","PodRoleNamePairs":[{"podName":"mysql-875777cc4-mysql-1","roleName":"primary","podUid":"ccf5126a-4784-4841-b238-4bf30f98b172"}]}]
2025-07-18T07:55:18Z INFO event send event success {"message": "{\"event\":\"Success\",\"operation\":\"checkRole\",\"originalRole\":\"secondary\",\"role\":\"{\\\"term\\\":\\\"1752825318001682\\\",\\\"PodRoleNamePairs\\\":[{\\\"podName\\\":\\\"mysql-875777cc4-mysql-1\\\",\\\"roleName\\\":\\\"primary\\\",\\\"podUid\\\":\\\"ccf5126a-4784-4841-b238-4bf30f98b172\\\"}]}\"}"}
Based on Chaos Mesh fault injection tests on various database engines managed by KubeBlocks (including MySQL, PostgreSQL, Redis, MongoDB, and SQLServer, etc.), the test results validated KubeBlocks' effectiveness in ensuring database high availability.
| Test Scenario | Test Metric | Test Result |
|---|---|---|
| PodChaos - Primary Pod Forced Deletion | Failover Time | MySQL/PostgreSQL/Redis/MongoDB ≤ 10 seconds; SQLServer Always On ≤ 30 seconds |
| Service Recovery | New primary node automatically takes over; application connection interruption ≤ 2 seconds | |
| Data Consistency | Zero data loss (ensured by WAL/Raft and other log synchronization) | |
| PodChaos - Single Replica Pod Continuous Restart | Service Availability | ≥ 99.9% (requests automatically routed to healthy nodes during replica reconstruction) |
| Replica Recovery Time | K8s restarts Pod within 30 seconds; data synchronization delay ≤ 5 seconds | |
| NetworkChaos - Primary Node Network Latency | Failover Trigger | MySQL Raft Group database engine liveness probe timeout (default 15 seconds) triggers automatic primary election |
| Split-Brain Protection | Raft consensus protocol prevents dual primaries; only majority partition can write | |
| Performance Impact | Request latency peak ≤ 35%; returns to normal after switchover | |
| NetworkChaos - 100% Packet Loss Between Primary and Secondary Nodes | Data Synchronization | No data loss during asynchronous replication interruption; automatically catches up after recovery |
| NetworkChaos - Network Partition Between Nodes | Partition Tolerance | Majority partition service remains available; minority partition rejects writes |
| StressChaos - Primary Node CPU Overload (100%) | Failover Trigger | Redis Sentinel primary node CPU sustained overload for 2 minutes triggers failover; new primary takes over; old primary automatically rejoins as replica after recovery |
| Resource Isolation | Secondary node performance unaffected (K8s cgroup isolation effective) | |
| StressChaos - Secondary Node Memory Pressure (OOM Simulation) | Process Recovery | K8s automatically restarts Pod within 60 seconds; service self-heals |
| Data Synchronization | Full synchronization between primary and secondary nodes after restart; no state leakage | |
| DNSChaos - Random Internal DNS Resolution Failures within Cluster | Service Discovery | Client retry mechanism ensures request success rate ≥ 99.9% |
| TimeChaos - Primary Node Clock Jumps Forward 2 Hours | Transaction Integrity | Committed transactions are not rolled back; cluster state consistent after clock calibration |
Through deep integration and practice of Chaos Mesh, KubeBlocks has initially established a standardized database high availability validation system, successfully addressing challenges in core fault scenarios such as Pod failures, network failures, resource pressure, time failures, and DNS failures. However, ensuring continuous high availability of database services is an endless journey. In the future, we plan to explore and practice in the following directions to continuously enhance KubeBlocks' availability assurance capabilities: